
Welcome to the Code Mines, our (mostly) weekly development blog on Administratum. In these posts we’ll be talking about the process of building Administratum, the thought behind some of the features, and our approach to making it the best tool for campaign management on the web.
If you want a software engineer to suffer, to relive their greatest moments of pain, then ask them about regular expressions.
If you want a software engineer to rejoice, to relive their greatest moments of triumph, then ask them about regular expressions.
But what are these strange little patterns? Why does everyone hate them, why does everyone love them, and how does Administratum (ab)use them? Let’s get to the bottom of regular expressions, deep in the heart of the Code Mines.
Be on Alert: Regex is Abound
A regular expression, frequently shortend to regex, is a way of matching patterns in text. But before that puts you to sleep, let’s look at some examples that will spice things up.
Suppose you are looking at a news ticker for important Goonhammer updates: Competitive Innovations here, Meatwatch there, all good things. But then these two stories come through:
Alert: Gregbot escaped his cage
Alert: Coffee reserves running low
To be sure, both of these are alarming. But while one is a catastrophe, the other is an XK-class end of world scenario. I’ll leave it as an exercise to the reader to determine which is which.
If the news ticker is relatively quiet, then you’ll have no issue catching these stories. But what if Goonhammer published dozens of stories per day? Stories with no substantive content, stories that were just clickbait, ad-filled, copy-pastes from other sites? Boy, that sounds miserable doesn’t it. It also sounds like you might miss these important alerts among such a deluge of trash!
You think to yourself, how can I listen to this feed for alerts? I see that there is a pattern in them, they all start with the word “Alert”. If only there was some way to express this pattern in a regular way …
/Alert/
The leading and trailing forward slash are just computer things that indicate it’s a regex. You can ignore them.
What you have here is a regular expression that matches the word “Alert”. You feed it some text, and it will let you know if it contains the word “Alert”. You hook it up to the news ticker, and lo and behold:
Alert: Gregbot escaped his cage
Alert: Coffee reserves running low
Great, you hear two friendly chimes as your regex is matching these stories! You pat yourself on the back for a job well done and get back to make plans for the soon-to-be-apocalypse that these stories foretell.
But then you get another chime. Goonhammer has posted another story and your regex found a match. You take off your gas mask and doff the rubber gloves, rushing to your computer only to find:
Hot Take: Red Alert 2 still rules
While this story is objectively true and a fantastic take, it’s not the type of alert you were looking for. Fortunately, you’ve only just scratched the surface of regular expressions. If you add just one character to the regular expression, we can (maybe) fix it:
/^Alert/
The entropy of a regex’s legibility begins to decay …
The ^ character is an assertion which matches the beginning of the text. This means the regex now only matches “Alert” if it’s the first word in the story. A job well done, another pat on the back, and another chime rings in the air!
Alert: Library of Congress closes, ‘Meatwatch too powerful to contain’
Another false alarm. True, this is a newsworthy event, but it’s not a surprise. Like gas prices going up in summer, or the United States failing to take meaningful action against gun violence after yet another tragedy, we all knew this was coming.
What we need is a regular expression that lets us filter the alert. Thinking through it, you could change the regex to Alert: Gregbot or Alert: Coffee, but then it’s only matching one or the other. What if you want both? Let’s complicate things and make it so:
/^Alert: (?:Coffee|Gregbot)/
We’re through the looking glass, people
This right here is what’s called a non-capturing group. The Coffee|Gregbot part matches either the word “Coffee” or the word “Gregbot”, and wrapping that inside (?:x) sets the bounds of the group. And what does it mean for a group to be “non-capturing”? More on that later, but let’s leave it as a mystery for now.
And surely you’ve got the regex correct now. It’s capturing exactly what you want. You kick up your feet and relax.
But the day grows long, and silence fills the air. Nary a chime to be heard, and the tension grows. Curious, you rise and walk to the ticker, only to find these stories staring at you.
Alert: Only hot takes and beef steaks will keep away Gregbot
Alert: There is no more coffee, all is lost
Alas! Both of these are chime-worthy, but the regex matched neither, and so we need to modify it further. Will the work never be done? Will the regular expression ever be complete? Obviously not, no software is ever truly “done”, but we can nonetheless make progress. There are two issues here.
The first issue is that the words we are looking for, “Gregbot” and “Coffee”, are not immediately after “Alert:” in these stories. We want to match a story where those words appear anywhere in the title, not just at the beginning.
The second issue is that “coffee” in the second story isn’t capitalized, and our regex is specifically looking for capital-c “Coffee”.
Once more into the code …
/^Alert:.*(?:[cC]offee|Gregbot)/
The looking glass is far, far behind us now
Now we have a regex that matches both of those stories. But what’s going on?
Let’s go over the easier of the two changes first, [cC]. This is a character class, a way of defining a set of characters to match against. In this case, it matches the character “c” or “C”. You might be thinking, but isn’t that what our non-capturing group from before is doing? Couldn’t we do (?:c|C) instead? Sure, that absolutely works! There are many ways of solving any problem in regular expressions. But character classes can do some interesting things that capture groups can’t.
For example [a-z] matches all lower case letters, a through z. If we want any single upper or lower case letter, we could use [a-zA-Z] and we could use [0-9] if we wanted any single-digit number. In fact, looking for single-digit numbers is so common, \d is a shorthand for that character class. Cool stuff.
Then we have the weirder of the two changes, .*. What’s going on here? Well, sometimes you want to match any ol’ character. You want a wildcard. That’s where . steps it. It’s also a character class, but instead of just letters or numbers, it matches any single character. Well, any character except line termination characters, but let’s ignore that.
As for the asterisk, that’s a quantifier. It’s a way of adjusting how many times you want to match something. There are many different quantifiers, but * indicates that the preceding item should be matched zero or more times.
Putting them together, .* means “match any character, as many times as you can“. This lets our regular expression scan through the story, looking for “coffee”, “Coffee”, or “Gregbot” anywhere in it.
And with that, the regular expression is complete. This little gem /^Alert:.*(?:[cC]offee|Gregbot)/ is perfect and flawless in every way.
And It Can’t Get Any More Complicated!
Except that it can and does, especially in any real-world application like Administratum. Speaking of, how does Administratum use regular expressions? After all, it doesn’t need to parse that many news feeds.
That’s the thing about regular expressions, they’re useful in all sorts of unexpected places. Anywhere that has a text-based problem, there exists a regex-based solution.
Inside Administratum, you can import units from Warhammer 40,000: The App via its sharing feature. This gives you a text printout of your army, which Administratum parses into individual units.
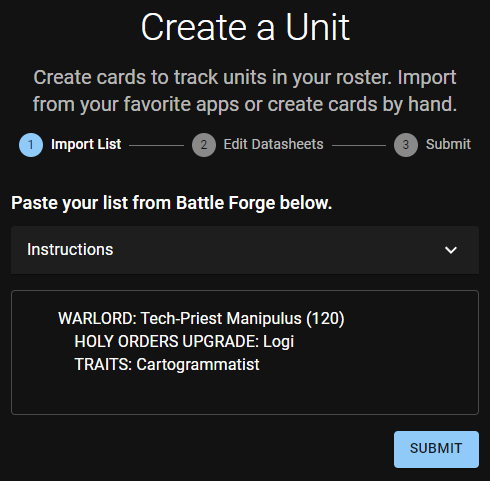
Parsing printouts like this is a perfect place for regex to shine. And here is the regular expression that Administratum uses to parse a warlord’s datasheet name and points.
/[ \t]*WARLORD: (.*) \((\d+)\)/
It could be worse
It starts off with [ \t]* which might look familiar, as it’s a character class. This class matches any number of spaces and/or tabs. Warhammer 40,000: The App exports army lists with tab characters, but many ways that these army lists get shared around automatically convert tab characters into spaces. So this regex matches either.
Then we have WARLORD: which, like Alert: earlier, simply matches that word. Then we have a space followed by (.*). You might remember .* from above; it means “match any character, as many times as you can“. By placing this inside parentheses, it is inside a capture group. Unlike the non-capturing group from above (note the lack of leading ?:), capture groups can be used to return the “captured” text. Instead of just saying “Did it match: yes/no” it can be used to say “It matched, and this is the text I found”. In fact, that’s exactly how Administratum figures out the datasheet name of a warlord!
Finally we have \((\d+)\). While this looks complicated, it’s simple once we break it down.
The \ character is an escape. It’s saying “Hey, I know the character next to me looks like a capture group, or character class, or whatever, but ignore that. Just treat it as plain text, alright?” So \( just matches the text literal “(“. Similarly, \) matches the text literal “)”.
Inside those two, we have another capture group that contains a character class of \d (which I briefly mentioned above matches any single digit number), followed by the quantifier +. This is similar to asterisk, but where * means “zero or more” matches, + means “one or more” matches. This capture group therefore looks for a number that is contained inside parenthesis, like “(120)”. And this is how Administratum figures out how many points a warlord costs!
Easy peasy
What Other Regular Expressions Does Administratum Use?
All together, Administratum uses about a dozen regular expressions to parse the output from Warhammer 40,000: The App. However, they are all quite similar, as the app has a fairly consistent data format. Take a look at some examples:
/[ \t]*TRAITS: (.+)/
This captures warlord traits from a warlord
This one is even simpler than capturing the datasheet name and points of the warlord. Using the above as a reference, it shouldn’t be hard to figure out what this is doing
/[ \t]*PSYCHIC POWERS: (.+)/
This captures psychic powers from a unit
I initially forgot to implement this. As an Admech player, I don’t have much call for psychic powers, and I forgot they existed when building the importer. It was a good couple days before someone let me know that Administratum was skipping psychic powers. Whoops, my bad. A good example of why you want other people testing your code, as it’s extremely easy to overlook things like this.
/[ \t]*(.+): (.+)/
This captures something from a something
This is the final regex that the importer runs when trying to parse a line. It captures generic things. It’s a catchall for upgrades that don’t otherwise fit neatly into something like a relic, sub-faction, warlord trait, etc.
When the other regular expressions run, their results are stored in variables with names like maybeWarlordTraits or maybePsychicPowers, which Administratum checks to see if there are matches and what has been captured. For this regular expression though, I have no idea what it’s capturing, so it’s stored in a variable named maybeSomething, and then added as a note on the unit.
Kind of a stupid variable name, but you know what they say: if it’s stupid and it works, it ain’t stupid.
I Thought You Said Regex Was Complicated?
All the above regexes are actually pretty simple. With a little explanation, you can figure out exactly what each is doing. But regex is not satiated. Regex hungers. Regex is an all consuming beast that grows and grows, getting scarier all the while.
Looking back at previous projects I’ve worked on, I’ve written some truly mean-spirited regular expressions. And I’ll leave you with the pièce de résistance.
About four years ago I was working on a project that converted my own custom markdown-esque language into well-formatted HTML and CSS that could be printed to PDFs. It was actually really cool, and I’m quite happy with it. I’d love to go back to it at some point, as I was able to generate some really cool homebrew for the game system Genesys.
All this was done via regular expressions.
You read that right. It parsed arbitrary markdown, including an absurd amount of custom directives for describing and rendering graphs, text formatting, and styling. It parsed all of that and generated the corresponding HTML. It even parsed its own HTML to insert styling information. How did it do this?
Painfully. Let’s look at just one of the dozens of regular expressions that powered that beast.
/<[^c>]*?class='([^’]*?)'[^>]*?>\s*(\\[^\s\\][\S]*)+? (.*?)<\/(.*?)>/g
This captures Cthulhu from R’lyeh
What is this even doing? What’s that /g at the end? Why would I write hundreds of lines of code that look like this? Why does this regular expression start with a Kirby dance emoji?
It’s dark, down here in the Code Mines. And some questions are best left unanswered.
Have any questions or feedback? Drop us a note in the comments below or email us at contact@goonhammer.com.
